Getting text and images out of a PDF can feel like trying to crack a safe. The good news is, you've got a couple of solid methods at your disposal. You can either copy and paste the text directly if it's a standard text-based file, or you can use an Optical Character Recognition (OCR) tool to work its magic on scanned documents. The right approach really hinges on what kind of PDF you're dealing with.
Your Guide To Effortless PDF Content Extraction

I've spent countless hours trying to wrestle valuable text and images out of locked-down PDFs. As a student, my biggest headache was turning dense lecture slides into usable study flashcards for my Notion workspace. It felt like a constant battle. This guide will show you exactly how I learned to pull content from any PDF and get it into my digital notes.
First, Know Your PDF
Before you can extract anything, you have to figure out what you're working with. Not all PDFs are built the same, and they generally fall into two camps:
- Text-Based (or "True") PDFs: These are the most common and the easiest to handle. The text is selectable, meaning you can highlight, copy, and paste it just like a Word document. They’re usually created directly from a word processor or other software.
- Image-Based (or Scanned) PDFs: Think of these as photographs of a document. You can't select any text because your computer sees the whole page as one big image. This is where OCR becomes your best friend.
Getting a handle on these files is a bigger deal than you might think. The global PDF software market was valued at USD 5.77 billion in 2025 and is projected to hit USD 8.93 billion by 2034. You can discover more insights about the PDF software market and see just how essential this skill has become.
I remember trying to copy notes from a scanned textbook for a final exam. I spent 20 minutes highlighting what I thought was text, but when I pasted it, nothing showed up. It was just a picture. Learning to spot the difference between a true PDF and an image file was the breakthrough that completely changed my study workflow.
Choosing Your PDF Extraction Method
To make it even clearer, here’s a quick comparison to help you choose the best extraction method for your situation.
| Method | Best For | Effort Level | Accuracy |
|---|---|---|---|
| Simple Copy & Paste | True/Text-Based PDFs with clean formatting. | Low | High (but can mess up formatting). |
| OCR Software | Scanned documents, image-based PDFs, or photos of text. | Medium | Varies; high on clear documents, lower on messy ones. |
Ultimately, identifying your PDF type upfront saves a ton of frustration and sets you on the quickest path to getting the content you need for your flashcards.
Mastering the Copy-Paste Method for Text-Based PDFs
Sometimes the simplest approach is the best one, and that often holds true for getting text out of a PDF. Your first move should always be to try the classic copy-paste. If you can click and drag your cursor to highlight text, you're in luck—you have a text-based PDF, which is the easiest kind to work with.
But if you've ever tried this, you know it's rarely a clean transfer. I remember pulling definitions from a dense academic journal for a Notion flashcard set, and the result was a disaster. The text pasted with bizarre line breaks mid-sentence, huge gaps between words, and all sorts of other formatting gremlins. It was completely unusable without a ton of manual cleanup.
The Smart Way to Copy and Paste
Here’s the trick I’ve relied on ever since. Instead of pasting directly into Notion, a Word doc, or wherever your final destination is, paste it into a plain text editor first. On Windows, that’s Notepad. On a Mac, use TextEdit. This simple action instantly strips away all the weird, invisible formatting the PDF was clinging to.
After that, it's much easier to spot and fix the leftover issues, like rejoining sentences that were awkwardly split. This little detour takes maybe 10 seconds, but it saves you an incredible amount of reformatting frustration down the line.
Pro-Tip: Once the text looks clean in your plain text editor, then you can copy it again and paste it into your Notion database. This way, the text will adopt Notion’s clean, native formatting instead of carrying over the PDF's messy baggage.
The general workflow for pulling content from a PDF is pretty straightforward, and this infographic gives you a great visual overview of the entire process.
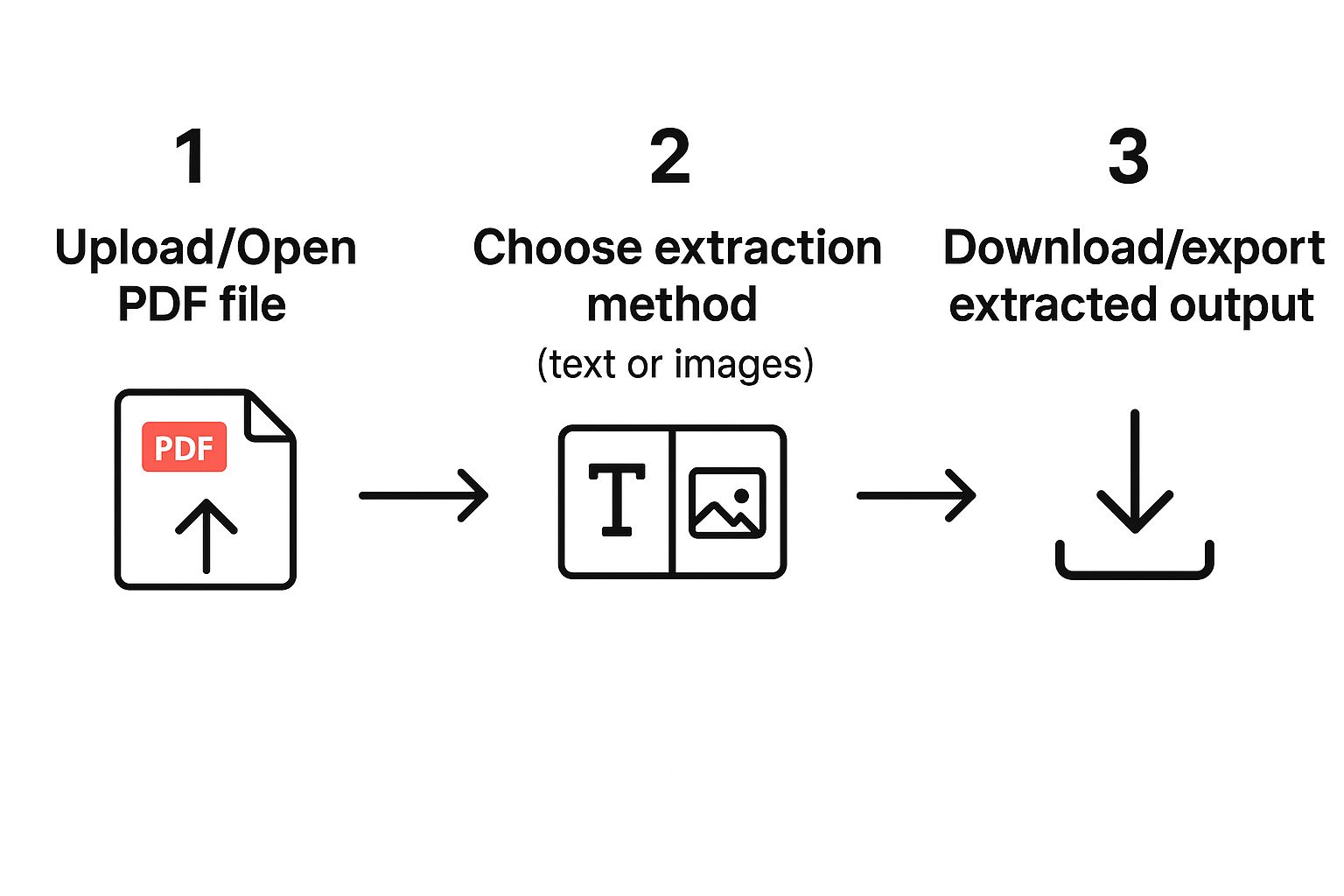
As you can see, it all starts with opening your file and then choosing the right extraction method for the job, whether that's a simple copy-paste or a more advanced tool.
This fundamental need to work with PDFs is a huge deal. The market for PDF reader software was valued at a staggering USD 1.96 billion in 2024 and is projected to hit USD 4.69 billion by 2031. That massive growth just shows how many of us are constantly searching for better ways to handle our documents. You can read more about the growth of the PDF market to get the full industry perspective.
Using OCR for Scanned PDFs and Images

So, what happens when you try to highlight text in a PDF, but nothing happens? It’s a frustratingly common scenario, especially with scanned textbook chapters, a professor's handwritten notes, or any PDF that's really just a flat image. When copy-paste fails you, your secret weapon is Optical Character Recognition (OCR).
Think of OCR as a digital translator for images. It meticulously scans a picture, identifies the shapes of letters and words, and converts them into actual, editable text. I had a huge "aha" moment with this during my second year of college. I was staring down a 50-page scanned primary source for a history class, and the thought of retyping everything was just soul-crushing.
Instead, I ran it through an OCR tool. In a matter of minutes, that entire image-based document became a searchable, editable file. That one step probably saved me days of mind-numbing work and let me jump right into analyzing the material.
Getting Started with OCR
To pull this off, you'll need a reliable OCR tool. The good news is that you've got plenty of options, from surprisingly powerful free services to more advanced, paid software.
- Free Tools: Google Drive actually has a fantastic built-in OCR feature. Just upload your scanned PDF, right-click on the file, and select "Open with > Google Docs." It'll automatically process the file and generate a new Doc with all the extracted text.
- Paid Tools: For more complex layouts or lower-quality scans, dedicated software like Adobe Acrobat Pro or other specialized online services deliver much higher accuracy.
This isn't just a niche student hack; it's big business. The data extraction market, which heavily relies on OCR, was valued at around USD 5.8 billion in 2023. It’s projected to explode to USD 41.6 billion by 2033, all thanks to the sheer volume of information locked away in unstructured files like PDFs. If you're curious, you can learn more about data extraction market trends to see just how important this tech is becoming.
Key Insight: The quality of your original scan is everything. A clear, well-lit image of typed text will give you fantastic results. A blurry photo of crumpled, handwritten notes? Not so much. Always start with the best quality scan you can get your hands on.
Let's walk through a quick example. You've got that scanned article. You upload the PDF to your OCR tool of choice. The software gets to work, "reading" the text from the image. Once it's done, you can simply copy or export the clean text and start building out your flashcards in Notion.
Extracting Images and Tables Like a Pro
https://www.youtube.com/embed/6Nv7g4NdYPY
Text is only half the story, right? So often, the most important information is locked away in the images, charts, and tables sprinkled throughout a PDF. I learned this the hard way while cramming for a medical exam. I desperately needed a high-quality anatomical diagram for a flashcard, but my quick screenshot resulted in a blurry, pixelated mess that was pretty much useless.
This is a super common problem when you're trying to pull content from a PDF, but thankfully, it's one you can easily solve. The secret is to stop taking screenshots and instead use tools that pull the original, high-resolution asset directly from the file. This way, your visuals stay sharp and your data remains perfectly structured.
Pulling High-Quality Images
Most modern PDF readers, including the free version of Adobe Acrobat, have tools for this built right in. Forget the screenshot command. Instead, look for an option to "export," "save," or "copy" the image itself.
In a lot of programs, you can simply right-click an image to bring up a context menu with a "Save Image As" or similar option. This saves the image file in its original quality, not a compressed, low-quality copy.
I do this all the time when I need a diagram for a Notion flashcard. The process is simple:
- Open my PDF and navigate to the diagram I need.
- Right-click the image and select the option to save it.
- Save it to my desktop, then just drag and drop it into my Notion page.
The difference in clarity between a screenshot and a direct extraction is absolutely night and day.
Handling Structured Data and Tables
Tables are a whole other beast. Trying to copy and paste them usually leaves you with a jumbled wall of text that’s impossible to read. When I'm faced with a complex table, I turn to specialized online tools designed specifically to extract tables from PDFs.
Many of these services let you upload a PDF, highlight the table you want, and then export it as a clean CSV or Excel file.
A quick story: I once had to analyze a ridiculously complex table from a quarterly financial report for an economics class. I used an online table extractor to convert it into a CSV. From there, I could just copy and paste the perfectly formatted data straight into a Notion database. It saved me what felt like hours of mind-numbing manual data entry. This is easily the best way to extract PDF tables while keeping the rows and columns perfectly intact.
Building Your Ultimate Notion Flashcard System
Alright, now for the fun part. We're going to take all that text and those images you just pulled from your PDF and build them into a seriously effective study machine. This is where we move beyond a simple two-column table and create a dynamic flashcard system right inside Notion. It’s how you turn static notes into an active recall tool that actually helps you remember things.
I personally used a system just like this for my biology courses, and it completely changed how I studied. It all starts with creating a new database in Notion. Just think of this as the main library for every single flashcard you'll make.
Setting Up Your Flashcard Database
Instead of a basic "front" and "back" setup, we're going to add a few smart properties. These properties act like tags or filters, giving you precise control over how you organize and review your flashcards.
Here’s the structure I’ve found works best:
- Topic (Select property): This is for categorizing your cards. For example, you might have topics like "Cell Division" or "Metabolism." It's perfect for when you need to focus your study session on one specific subject.
- Review Date (Date property): Absolutely essential for spaced repetition. Once you review a card, you'll simply set this date for the next time you want to see it.
- Confidence (Select property): This is a straightforward way to track your progress with each card. I like to use simple tags like "New," "Learning," and "Mastered."
This is what a well-organized Notion database can look like once you get going.

As you can see, you can combine different views, like a table for raw data and a calendar to get a visual handle on your study schedule. It makes managing everything much less of a headache.
This database structure is the foundation of the whole system. After you extract PDF content, you're not just pasting it randomly; you're plugging it into an organized machine built for learning. Imagine being able to instantly filter for cards tagged "Learning" under the "Metabolism" topic that are due for review today. That's the power we're building.
The real magic here, though, is getting that classic front/back flashcard feel. We can do this easily with Notion's toggle list feature. For each entry in your database, you’ll create a toggle. The question or prompt goes on the outside, and the answer gets tucked away inside.
This simple setup forces you to actively try and remember the answer before you click to reveal it. That’s the entire principle behind what makes flashcards so effective. It’s a small detail, but it makes a huge difference compared to just passively reading your notes.
Dealing with Common Extraction Headaches
Even with the best software, pulling content from a PDF isn't always a smooth ride. It’s just the nature of the beast. I’ve spent countless hours wrestling with stubborn documents, and I've found that most extraction problems boil down to a few common culprits. Here’s how I handle them.
Why Does My Copied Text Look Like Gibberish?
You’ve probably seen this before. You highlight a clean-looking paragraph, hit copy, and paste it, only to get a jumbled mess full of weird line breaks and spacing. It's incredibly frustrating, but it's a classic PDF problem.
This usually means the PDF is built with hidden formatting, like invisible columns or tables, that your clipboard just can’t interpret correctly. The simplest solution? Paste the text into a plain text editor first. I use Notepad on Windows or TextEdit on Mac for this. It strips away all that junk formatting, leaving you with clean text. If it still looks garbled, you're almost certainly dealing with a scanned image, not a true text-based PDF. In that case, you'll need OCR software to make the text selectable.
My Go-To Trick: Pasting into a plain text editor is the first thing I do when text gets messy. It’s a simple step that solves the problem 90% of the time. If you're learning how to extract PDF text, this will save you a ton of headaches.
What About Password-Protected PDFs?
This one's a bit tricky, and it really depends on the kind of password protection. If the PDF requires a password just to open and view the file, you're pretty much out of luck without it.
However, some PDFs have a different kind of lock—a "permissions" password that restricts actions like printing or copying text, even if you can open the file. Some specialized extraction tools can get around this, but you should always make sure you have the right to access and use that content before attempting to bypass any restrictions.
Ready to turn your PDFs into powerful study tools without the headache? PDFFlashcards lets you seamlessly extract content and create flashcards that are instantly exportable to Notion. Start building your flashcard system today!